1. Introduction
Recently, I’ve been reviewing the different techniques I’ve come across in LLM inference, and I decided to organize them into a blog post.
2. Key Terms and Optimization Methods
LLM inference can be optimized at several levels — from smarter scheduling algorithms, to tweaks in model structure, all the way down to GPU kernels. Below is a glossary of popular techniques.
General Terms
- Prefill phase – Processing the input prompt and generating the very first token.
- Decode phase – Generating subsequent tokens one by one.
- TTFT (Time to First Token) – How long it takes to produce the first output token.
- TTIT (Time to Intermediate Token) – The time taken to generate intermediate tokens.
2.1 Algorithm-Level Techniques
These methods don’t change the model’s fundamental architecture, but optimize how the model is used in inference time.
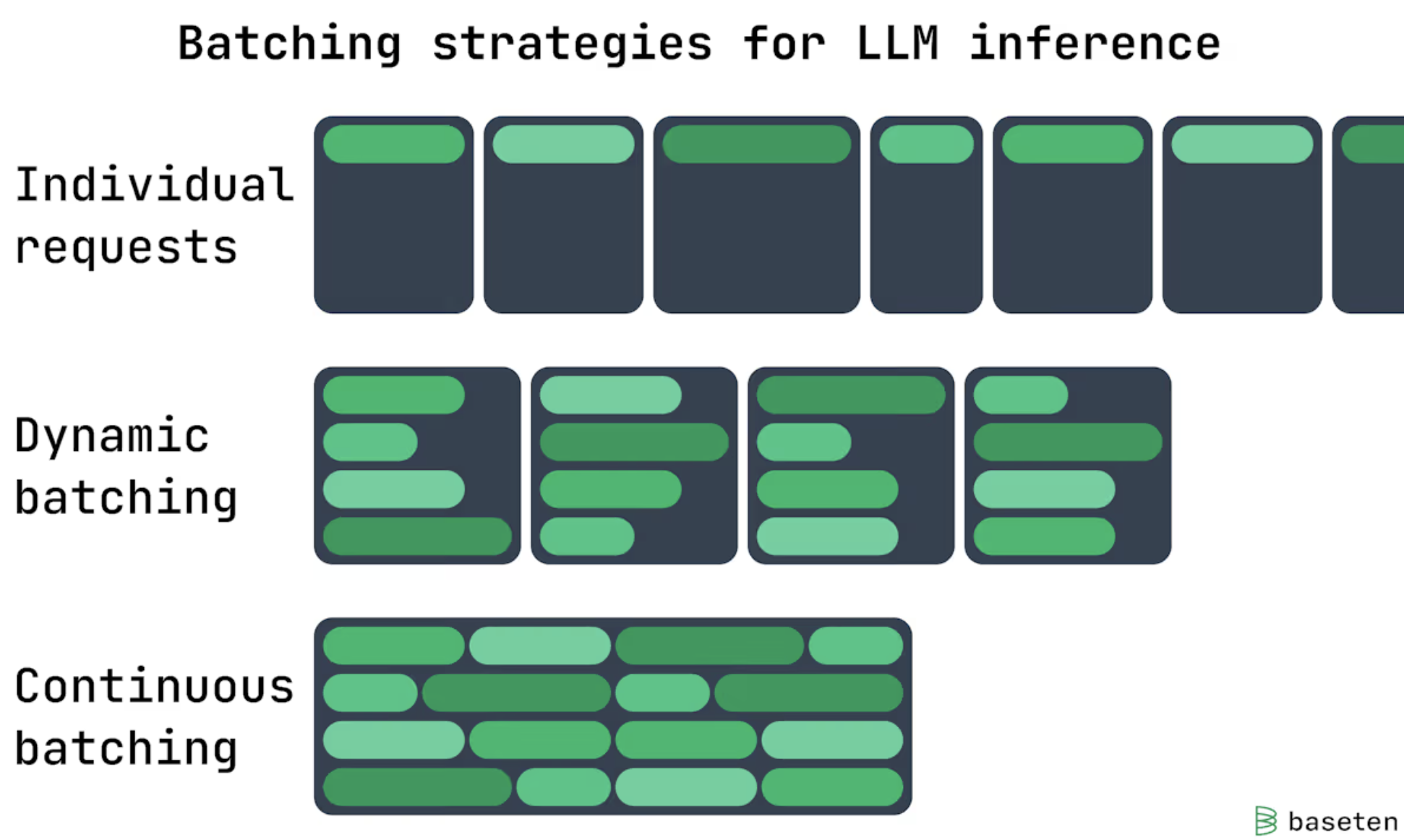
2.1.1 Continuous Batching (In-flight Batching)
What it is: A scheduling strategy where incoming requests are batched on the fly so GPUs stay busy. Unlike traditional static batching, where a batch is processed as a whole and all requests must wait for the slowest one to finish, continuous batching allows the system to immediately start processing the next request as soon as any request in the current batch completes.
Benefit: Increase GPU utilization and throughput.
Reading Materials
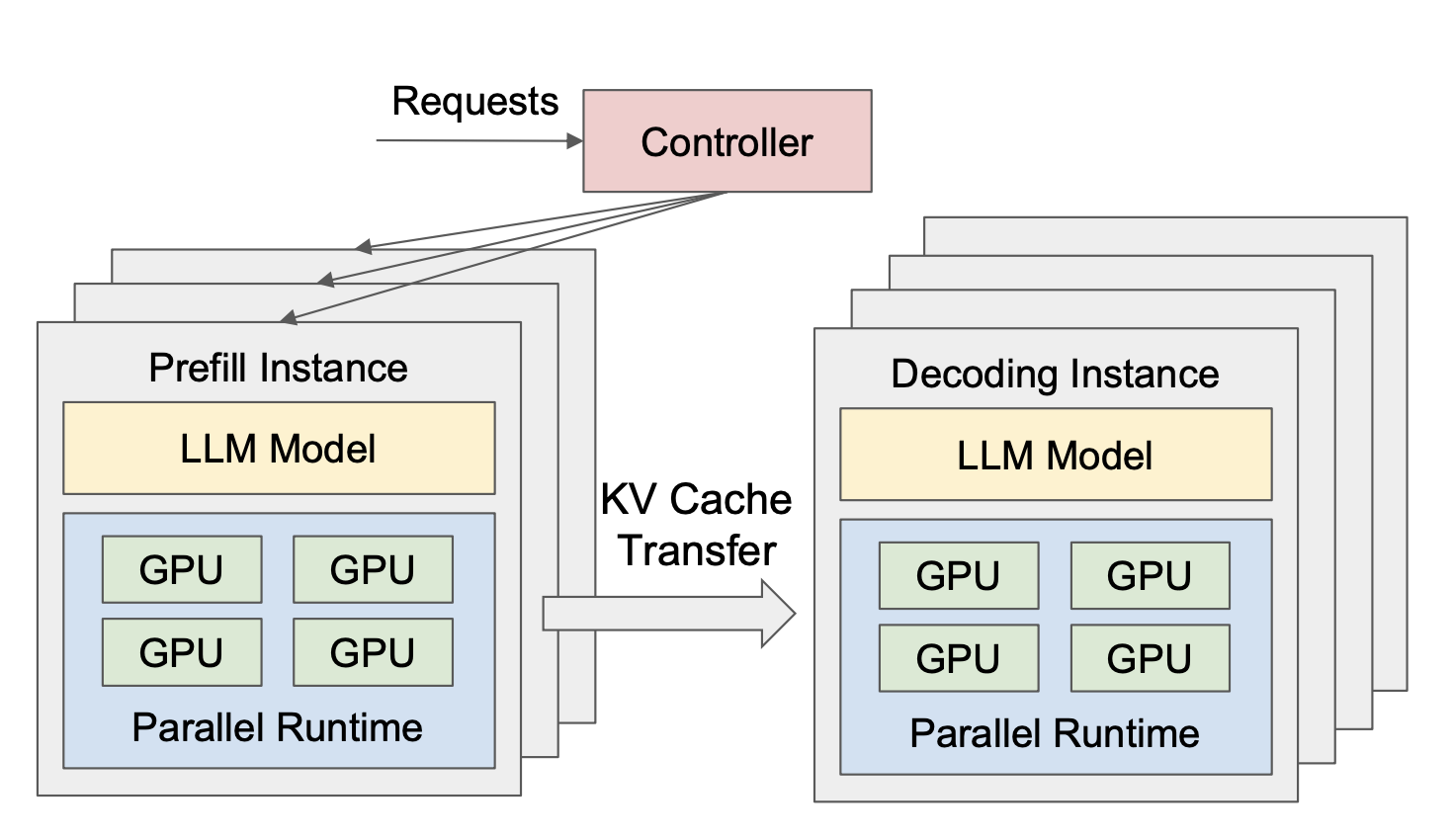
2.1.2 Prefill-Decode Disaggregation
What it is: Instead of handling the prefill phase and the decode phase in the same service, PD-Disagg separates them separately. One set of GPUs handles the prefill phase, while another set handles the decode phase, with fast data transfer of intermediate results between them.
Benefit: Improve the overall throughput, especially for the cases with TTFT and TTIT constraints.
Reading Materials:
- DistServe: https://arxiv.org/abs/2401.09670
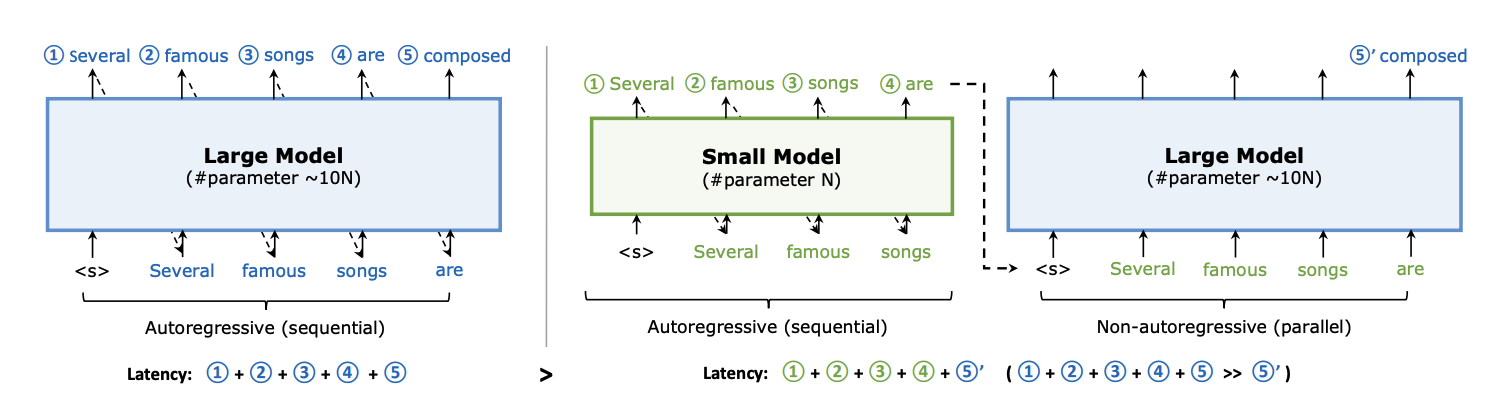
2.1.3 Parallel Decoding
What it is: Parallel Decoding is a technique to break the usual one-token-at-a-time generation bottleneck by predicting multiple tokens in parallel. It uses a “guess and verify” approach: a faster drafter generates several next tokens and then be verified with the original LLM model in parallel, accepting matching tokens and rejecting others.
Benefit: Reduce latency.
Reading Materials:
- Speculative Decoding: https://arxiv.org/pdf/2211.17192
- https://arxiv.org/pdf/2302.07863
- Eagle3: https://arxiv.org/pdf/2503.01840
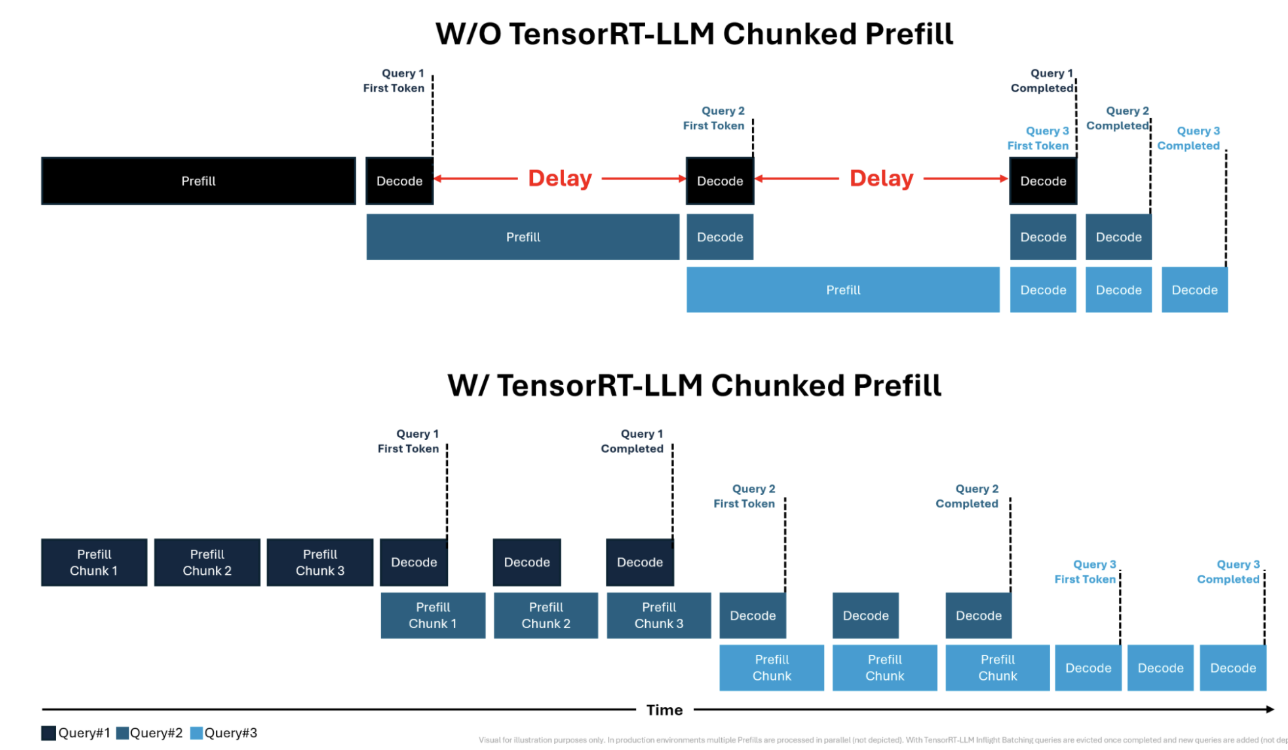
2.1.4 Chunked Prefill
What it is: Splits a long input prompt into smaller chunks for faster processing. This prevents the prefill phase from becoming a bottleneck, enables more parallelization with decode phase tokens, and increases GPU utilization.
Benefit: Better throughput and more stable TTIT.
Reading Materials:
- Blog from Nvidia: link
- SARATHI: https://arxiv.org/pdf/2308.16369
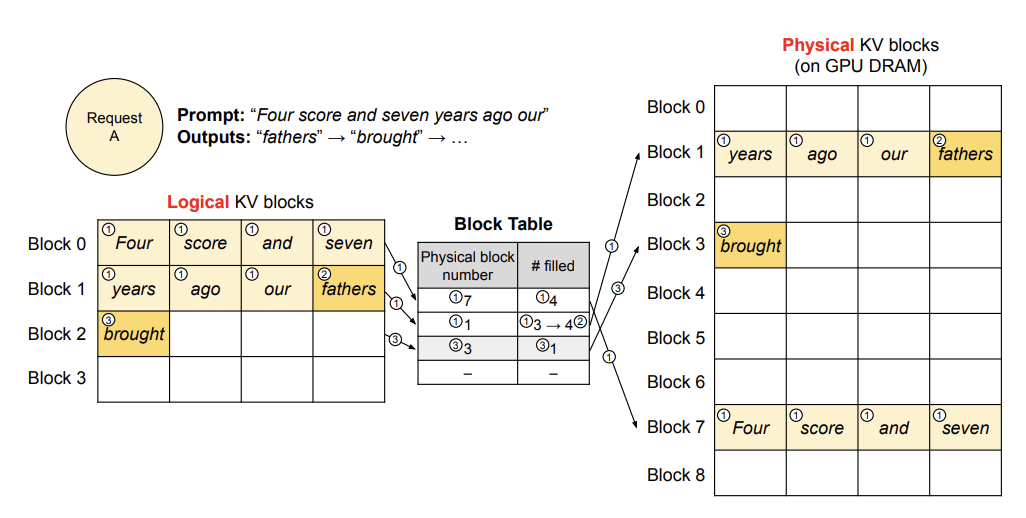
2.1.5 Paged Attention
What it is: Partitions the model’s attention KV cache into smaller fixed-size blocks or “pages” instead of one contiguous large block.
Benefit: Reduce memory waste and free up more memory, enabling support for longer prompts and larger batch sizes.
Reading Materials:
- PagedAttention: https://arxiv.org/abs/2309.06180
- vLLM Paged Attention: link
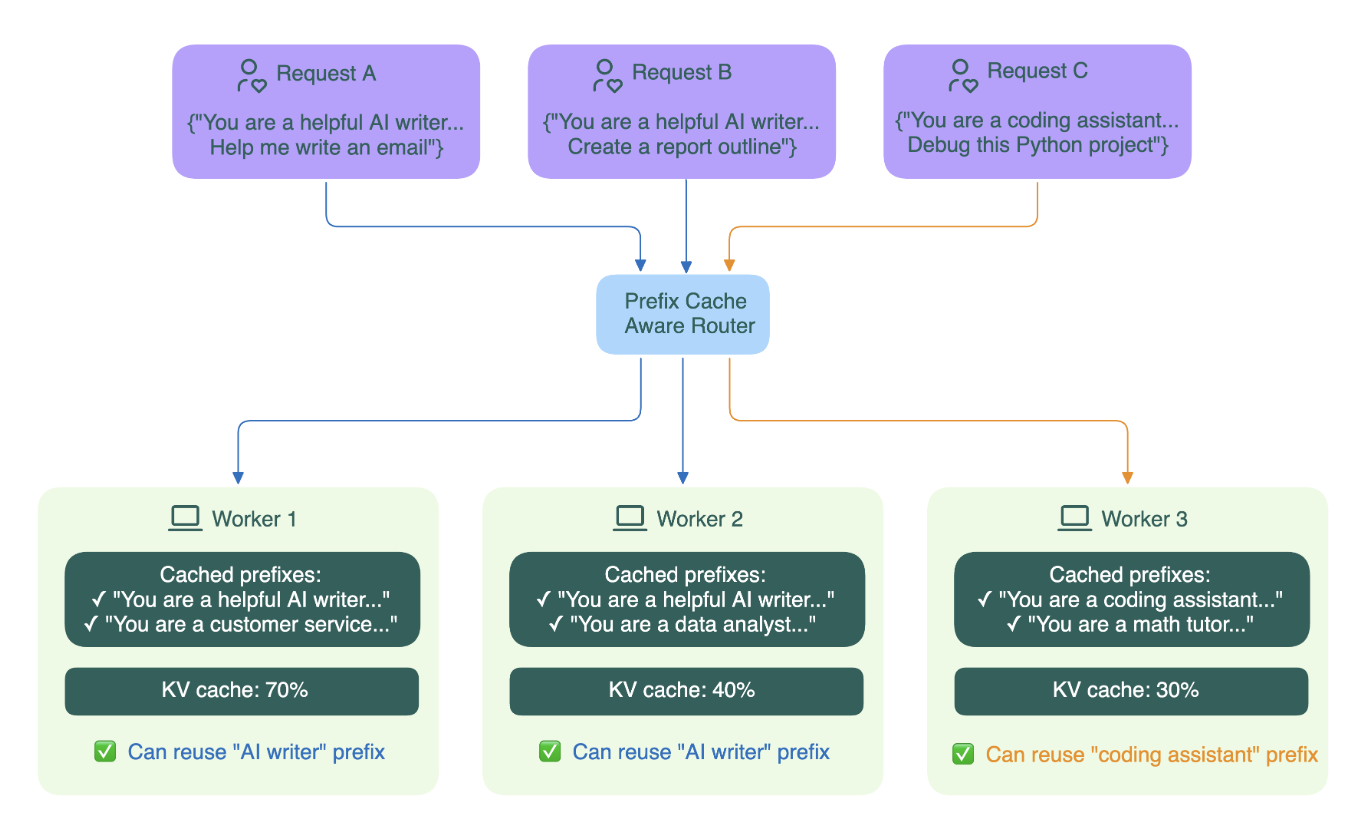
2.1.6 Prefix Cache
What it is: A caching strategy that reuses computation for repeated prompt prefixes across multiple requests.
Benefit: Reduce latency.
Reading Materials:
- Blog from BentoML: link
- SGLang: https://arxiv.org/pdf/2312.07104
- MARCON: https://arxiv.org/pdf/2411.19379
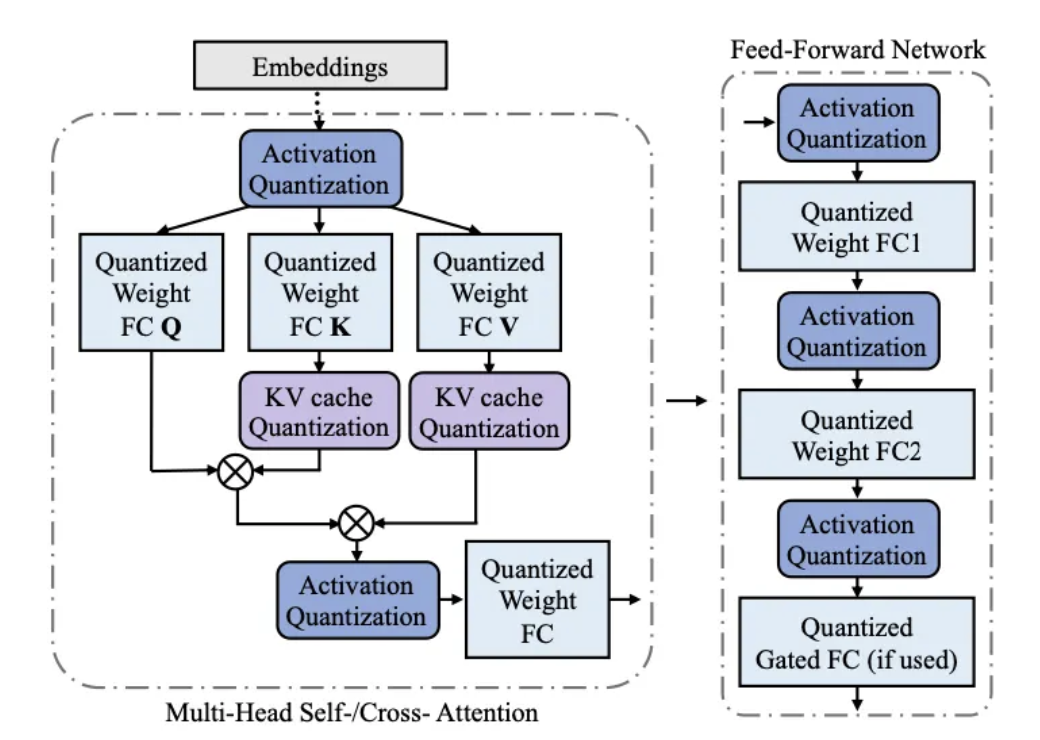
2.1.7 Quantization
What it is: Reducing the precision used for model parameters (and, in some cases, activations or the KV cache)—for example, switching from 16-bit floating-point to 8-bit integer representations—to save resources while maintaining reasonable accuracy.
Benefit: Reduces memory requirements and improves both latency and throughput
Trade-offs: May slightly reduce model accuracy
Reading Materials:
- https://arxiv.org/pdf/2208.07339
- https://arxiv.org/pdf/2411.02530
- Blog from medium: link
2.2 Model Structure Changes
I don’t have the time to dive deep into these yet, so for now I’ll just leave some terms here. If I get more familiar with them, I plan to write a follow-up article.
- Grouped Query Attention (GQA)
- Mixture of Experts (MoE)
- Distillation
2.3 Kernel-Level Optimizations
Same as above — just dropping the terms for now. I’ll revisit these in more detail later.
- Flash Attention
- Fused Kernels
3. Final Thoughts
Writing down and organizing these terms really helped me revisit concepts I often hear but hadn’t fully sorted out. Hopefully, this post also adds something useful to your own knowledge network :)